Advanced Model Handling in TIAToolbox¶
Click to open in: [GitHub][Colab]
About this demo¶
This notebook demonstrates advanced techniques on how to use TIAToolbox models with your current workflow and how you can integrate your solutions into the TIAToolbox model framework. By doing so, you will be able to utilize extensively tested TIAToolbox tools in your experiments and speed up your computational pathology research. Notice, in this notebook, we assume that you are an advanced user of TIAToolbox who is familiar with object-oriented programming concepts in Python and TIAToolbox models framework. To make yourself familiar with how TIAToolbox models work, we invite you to have a look at our example notebooks on patch classification and semantic segmentation in histology images/WSIs or you can study the documentation and the code base on these matters.
When thinking of either using the TIAToolbox models in your application or expanding it to fit your needs, several scenarios can be imagined. The most common scenarios and their solutions are briefly listed below:
Instead of pretrained models embedded in TIAToolbox’s repository, you want to use your own deep learning model (in Pytorch) in the TIAToolbox prediction workflow.
You can create your model by following the same protocol as the TIAToolbox model does and provide it to the predictor.
Your input data is of an exotic form which the TIAToolbox data stream functionality does not support by default.
You will need to subclass the
WSIPatchDatasetor related classes in the TIAToolbox to roll your own input form and provide the class for predictor construction.
Note that the output should still fit with existing deep learning models in the toolbox.
Other cases can be imagined, like when the existing merging strategy in the TIAToolbox does not fit your method for WSI processes. In this case, it is very likely that you have to overwrite a large portion of the existing workflow in the TIAToolbox which is beyond the scope of this example. However, if you learn the principles in this notebook, you will be able to find a way around that problem as well.
In this notebook, the SemanticSegmentor and its kit will be the base for the predictor workflow which we want to adapt to the mentioned scenarios.
Downloading the required files¶
We download, over the internet, image files used for the purpose of this notebook.
# These file name are used for
img_file_name = Path("./tmp/sample_tile.tif")
wsi_file_name = Path("./tmp/sample_wsi.svs")
class_names_file = Path("./tmp/imagenet_classes.txt")
imagenet_samples_name = Path("./tmp/imagenet_samples.zip")
logger.info("Download has started. Please wait...")
# Downloading sample image tile
download_data(
"https://huggingface.co/datasets/TIACentre/TIAToolBox_Remote_Samples/resolve/main/sample_imgs/tile_mif.tif",
img_file_name,
)
# Downloading sample whole-slide image
download_data(
"https://huggingface.co/datasets/TIACentre/TIAToolBox_Remote_Samples/resolve/main/sample_wsis/wsi_2000x2000_blur.svs",
wsi_file_name,
)
# Download some samples of imagenet to test the external models
download_data(
"https://huggingface.co/datasets/TIACentre/TIAToolBox_Remote_Samples/resolve/main/sample_imgs/imagenet_samples.zip",
imagenet_samples_name,
)
# Unzip it!
with ZipFile(imagenet_samples_name, "r") as zipobj:
zipobj.extractall(path="./tmp")
# Downloading imagenet class names
download_data(
"https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt",
class_names_file,
)
logger.info("Download is complete.")
|2026-02-24|14:43:04.492| [INFO] Download has started. Please wait...
|2026-02-24|14:43:05.693| [INFO] Download is complete.
1. Injecting your model into the TIAToolbox prediction framework¶
This topic has been already covered in the semantic segmentation notebook, however, we explain it more technically here. In order for your model to be appropriate to fit in the TIAToolbox framework, it has to have the following structure:
# ModelABC class
from tiatoolbox.models.abc import ModelABC
class Model(ModelABC):
def __init__(self: ModelABC) -> None:
# your code here
pass
@staticmethod
def infer_batch(self: ModelABC) -> None:
# your code here
pass
@staticmethod
def preproc() -> None:
# your code here
pass
@staticmethod
def postproc() -> None:
# your code here
pass
def forward(self: : ModelABC) -> None:
# your code here
pass
First and foremost, the Model class should inherit from from TIAToolbox’s ModelABC abstract class which is based on Pytorch’s nn.Module class. In other words, the TIAToolbox only works with Pytorch models which which have the above structure. All infer_batch, preproc, postproc, and forward methods have particular functionality that is explained in the ModelABC class. However, in order to demonstrate how the structure can be used, we define here a new model to perform focus scoring i.e., a model that measures how much each pixel in the input image is blurred. As we realize directly from the model purpose, it works in the same way that a semantic segmentation model works (applying two convolutional kernels to the input image) and therefore it can be directly fitted in the current workflow. We define it in the same protocol as the ABC above.
class BlurModel(ModelABC):
"""Example model which can be used for image blurring."""
def __init__(self: ModelABC) -> None:
"""Initialize BlurModel."""
super().__init__()
self.to_gray = torchvision.transforms.Grayscale()
kernel_gauss = np.array(
[
[0.00e00, 0.00e00, 0.00e00, 0.00e00, 0.00e00, 0.00e00, 0.00e00],
[0.00e00, 0.00e00, 0.00e00, 0.00e00, 0.00e00, 0.00e00, 0.00e00],
[0.00e00, 0.00e00, 3.78e-44, 1.93e-22, 3.78e-44, 0.00e00, 0.00e00],
[0.00e00, 0.00e00, 1.93e-22, 1.00e00, 1.93e-22, 0.00e00, 0.00e00],
[0.00e00, 0.00e00, 3.78e-44, 1.93e-22, 3.78e-44, 0.00e00, 0.00e00],
[0.00e00, 0.00e00, 0.00e00, 0.00e00, 0.00e00, 0.00e00, 0.00e00],
[0.00e00, 0.00e00, 0.00e00, 0.00e00, 0.00e00, 0.00e00, 0.00e00],
],
dtype=np.float32,
)
kernel_laplace = np.array(
[[1.0, 1.0, 1.0], [1.0, -8.0, 1.0], [1.0, 1.0, 1.0]],
dtype=np.float32,
)
# out_channels,in_channels,H,W
kernel_gauss = torch.from_numpy(kernel_gauss[None, None])
kernel_laplace = torch.from_numpy(kernel_laplace[None, None])
self.register_buffer("kernel_gauss", kernel_gauss)
self.register_buffer("kernel_laplace", kernel_laplace)
@staticmethod
def preproc(image: np.ndarray) -> np.ndarray:
"""Pre-processing function."""
return image
@staticmethod
def postproc(image: np.ndarray) -> np.ndarray:
"""Post-processing function."""
return image
def forward(self: ModelABC, img_list: list) -> torch.nn.Module:
"""Model forward function."""
# must be rgb input
img_list = self.to_gray(img_list)
laplace = F.conv2d(img_list, self.kernel_laplace, padding="same")
return F.conv2d(torch.abs(laplace), self.kernel_gauss, padding="same")
@staticmethod
def infer_batch(
model: torch.nn.Module, img_list: list, device: str
) -> list[np.ndarray]:
"""Model inference."""
img_list = img_list.to("cuda").type(torch.float32)
img_list = img_list.permute(0, 3, 1, 2).contiguous()
img_list = img_list.to(device)
model = model.to(device)
with torch.no_grad():
output = model(img_list)
output = output.permute(0, 2, 3, 1) # to NCHW
return output.cpu().numpy()
Now, let’s create a TIAToolbox segmentor that uses the model defined above.
Before that, we also need to define the Input/Output configuration expected by the model. In TIAToolbox, the IOSegmentorConfig class is used to set these configurations, as we have done in the cell below. (For more information on IOSegmentorConfig and SemanticSegmentor parameters, please refer to documentations or semantic segmentation notebook):
# Defining ioconfig
iostate = IOSegmentorConfig(
input_resolutions=[
{"units": "mpp", "resolution": 1.0},
],
output_resolutions=[
{"units": "mpp", "resolution": 1.0},
],
patch_input_shape=[512, 512],
patch_output_shape=[512, 512],
stride_shape=[512, 512],
save_resolution={"units": "mpp", "resolution": 1.0},
)
# Setting the save directory and delete previous results
wsi_prediction_dir = "./tmp/wsi_prediction/"
rmdir(wsi_prediction_dir)
# Creating the model
model = BlurModel()
# Creating a SemanticSegmentor using our model and start prediction
segmentor = SemanticSegmentor(model=model, num_workers=WORKERS, batch_size=1)
|2026-02-24|14:43:21.033| [WARNING] GPU is not compatible with torch.compile. Compatible GPUs include NVIDIA V100, A100, and H100. Speedup numbers may be lower than expected.
wsi_output = segmentor.run(
[wsi_file_name],
patch_mode=False,
device=device,
ioconfig=iostate,
save_dir=wsi_prediction_dir,
overwrite=True,
)
Now we check the prediction and source image to see if our model worked as expected.
reader = WSIReader.open(wsi_file_name)
thumb = reader.slide_thumbnail(
resolution=iostate.save_resolution["resolution"],
units=iostate.save_resolution["units"],
)
model_output = zarr.open(wsi_output[wsi_file_name], mode="r")
predictions = model_output["predictions"]
logger.info(
"Raw prediction dimensions: (%d, %d, %d)",
predictions.shape[0],
predictions.shape[1],
predictions.shape[2],
)
ax = plt.subplot(1, 2, 1)
(
plt.imshow(thumb),
plt.xlabel("WSI thumbnail"),
ax.axes.xaxis.set_ticks(
[],
),
ax.axes.yaxis.set_ticks([]),
)
ax = plt.subplot(1, 2, 2)
(
plt.imshow(predictions[..., -1]),
plt.xlabel("Focus map"),
ax.axes.xaxis.set_ticks(
[],
),
ax.axes.yaxis.set_ticks([]),
)
|2026-02-24|14:43:25.519| [INFO] Raw prediction dimensions: (460, 460, 1)
(<matplotlib.image.AxesImage at 0x70d9a0b592d0>,
Text(0.5, 0, 'Focus map'),
[],
[])
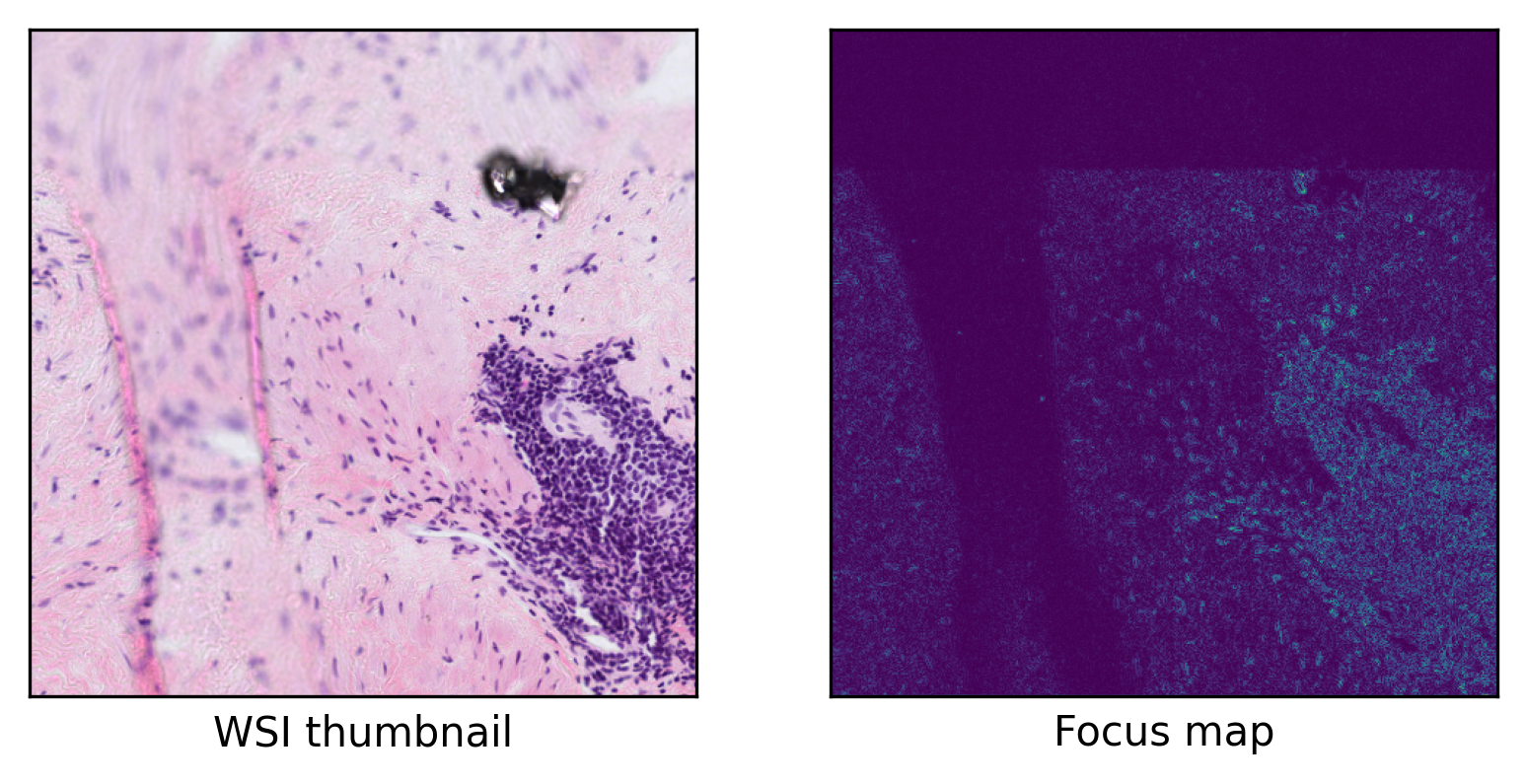
As you can see, our model successfully detects focused regions of the input WSI. In this example, we used a small WSI for the sake of low computation but you can test its functionality on any sample of your choice. In any case, the only thing that the user needs to provide is the model (with its weights loaded) and the TIAToolbox will take care of WSI processing, patch extraction, prediction aggregation, and multi-processing handling. When defining your model, you can even add your desired preprocessing function (for example, stain normalization) through the preproc method to be applied on each patch prior to inference.
To once again see how easy it is to use an external model in TIAToolbox’s semantic segmentation class, we summarize in pseudo-code, as below:
# 1- Define the PyTorch model and load weights
model = get_CNN() # model should follow tiatoolbox.model.abc.ModelABC
# 2- Define the segmentor and IOconfig
segmentor = SemanticSegmentor(model=model)
ioconfig = IOSegmentorConfig(...)
# 3- Run the prediction
output = segmentor.run([img_paths], save_dir, ioconfig, ...)
Injecting pretrained patch classification models¶
There are two ways in TIAToolbox that you can use your own pretrained classification models. The first way if to use TIAToolbox pretrained classification models, a list of which is available here. With this option, you can override the model weights with your own set of fine-tuned weights via the pretrained_weights argument (the argument is case insensitive).
However, sometimes you want to use a pretrained model that has not been implemented in the TIAToolbox framework.
We can use the same principles explained in the previous example to use an externally pretrained model in the TIAToolbox pipeline. In the example below, we show how to import a native torchvision pretrained model (not included in the TIAToolbox repository) and use it in the TIAToolbox patch prediction pipeline.
The first step is to import the model with its weights loaded and then we need to add some methods to the model class so that it would be suitable for a TIAToolbox pipeline (the model class should follow the tiatoolbox.models.abc.ModelABC structure).
transform = transforms.Compose(
[
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
],
)
# Define the pretrained model and load the weights
external_model = inception_v3(pretrained=True)
external_model.eval()
# define the methods needed for `tiatoolbox.models.abc.ModelABC abstract` class.
def infer_batch(
model: torch.nn.Module,
batch_data: np.ndarray | torch.Tensor,
device: str,
) -> np.ndarray:
"""Model inference on a batch of images."""
model.eval()
imgs = batch_data
imgs = imgs.to(device).type(torch.float32)
with torch.inference_mode():
logits = model(imgs)
probs = F.softmax(logits, 1)
return probs.cpu().numpy()
def postproc_func(output: np.ndarray) -> np.ndarray:
"""Pre-processing function."""
return output
def preproc_func(img: np.ndarray) -> np.ndarray:
"""Post-processing function."""
pil_image = Image.fromarray(img)
transformed = transform(pil_image)
return np.array(transformed)
# add the methods to the `external_model` class
external_model.infer_batch = infer_batch
external_model.preproc_func = preproc_func
external_model.postproc_func = postproc_func
Based on our knowledge of the imported external model, which is an imagenet pretrained inception_v3 CNN model, and the requirements of the TIAToolbox friendly model class, we have added infer_batch, postproc_func, and preproc_func methods to the external_model class. These functions apply the appropriate pre and post-processing on the image and model predictions, respectively. The design of these functions should be based on the external model and the problem at hand. You can follow the above cell example or the code in the TIAToolbox UNet architecture to be inspired and get an idea of what you need to do to suit your application (problem).
Now that we have our external_model ready, we just need to define the IOPatchPredictorConfig for data control and instantiate the PatchPredictor, which can ultimately be used for patch prediction. In the cell below, we have applied the external_model to a subset of 4 images from the “ImageNet” dataset.
external_ioconfig = IOPatchPredictorConfig(
input_resolutions=[{"units": "mpp", "resolution": 0.5}],
patch_input_shape=[224, 224],
stride_shape=[224, 224],
)
# 3. Define the patch predictor
external_predictor = PatchPredictor(model=external_model, batch_size=64)
# First, find the patch addresses
imagenet_files = list(Path("./tmp/imagenet/").glob("*.jpeg"))
# Now call the predict function on the patches
external_output = external_predictor.run(
images=imagenet_files,
patch_mode=True,
ioconfig=external_ioconfig,
return_probabilities=True,
return_labels=False,
device=device,
)
Now let’s see if each class has been correctly predicted by showing the sample images and their prediction’s “class:probability”.
# Load imagenet classes
with Path(class_names_file).open() as f:
classes = [line.strip() for line in f.readlines()]
# Showing the input images and their predicted classes
num_pics = len(imagenet_files)
for i, img_file in enumerate(imagenet_files):
img = imread(img_file)
cls_idx = np.argmax(external_output["probabilities"][i])
cls_prob = external_output["probabilities"][i][cls_idx]
cls_name = classes[cls_idx]
ax = plt.subplot(1, num_pics, i + 1)
(
plt.imshow(img),
plt.xlabel(
"{}:{:.2f}".format(cls_name.split(" ")[0], cls_prob),
),
ax.axes.xaxis.set_ticks([]),
ax.axes.yaxis.set_ticks([]),
)
